

WoolyAI Acceleration Service
GPU service with GPU core and memory resources used billing
About
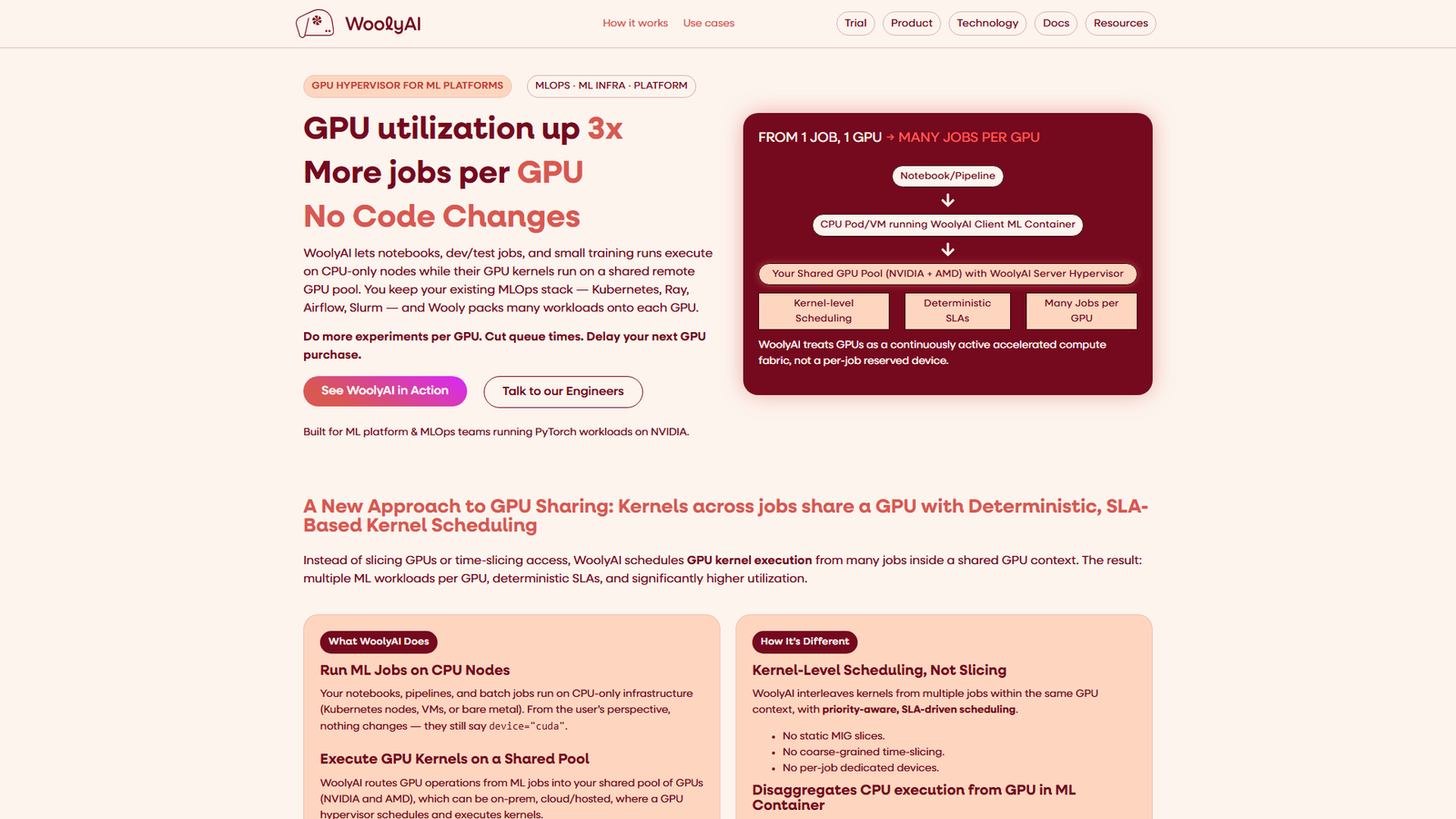
WoolyAI is a GPU Hypervisor for ML Platforms, targeting MLOps and ML Infra teams running PyTorch workloads on NVIDIA and AMD GPUs. It enables notebooks, dev/test jobs, and small training runs to execute on CPU-only nodes while their GPU kernels are routed to a shared remote GPU pool. This approach, featuring kernel-level scheduling, aims to increase GPU utilization by up to 3x, reduce queue times, and delay new GPU purchases without requiring any code changes to existing ML containers or MLOps stacks (Kubernetes, Ray, Airflow, Slurm). Key use cases include interactive development, hyperparameter optimization, multi-model pipelines, inference with SLAs, pre-production canary training, and integrating multi-vendor GPU fleets.
Categories & Tags
Color Palette
Background White
#FFFFFF
Text Dark Grey
#333333
Accent Blue
#007bff
Typography
Sans-serif
Heading
Sans-serif
Body
Design Review
Similar Products

Clear for Slack
Clear messages get answered quicker

Griply 2026
Achieve your goals with a goal-oriented task manager

vibecoder.date
Find who you vibe with, git commit to love

HappyMail
We made email simple again

Blober.io
The easiest way to transfer files between cloud providers.

Supaguard
Scan, Detect & Protect Your Supabase Data

Timelines Time Tracking 4
Track your time to achieve your New Year resolutions.

SoftReveal — Reveal less. Engage more.
Hide Content, Reveal on Click

CalPal
The notebook calculator that thinks for you (now with AI).

Reword
Rewrite messages without leaving your workflow

Radial
Your shortcuts, one gesture away

MoovAI
Launch viral AI ads & pro social content in minutes