

SelfHostLLM
Calculate the GPU memory you need for LLM inference
About
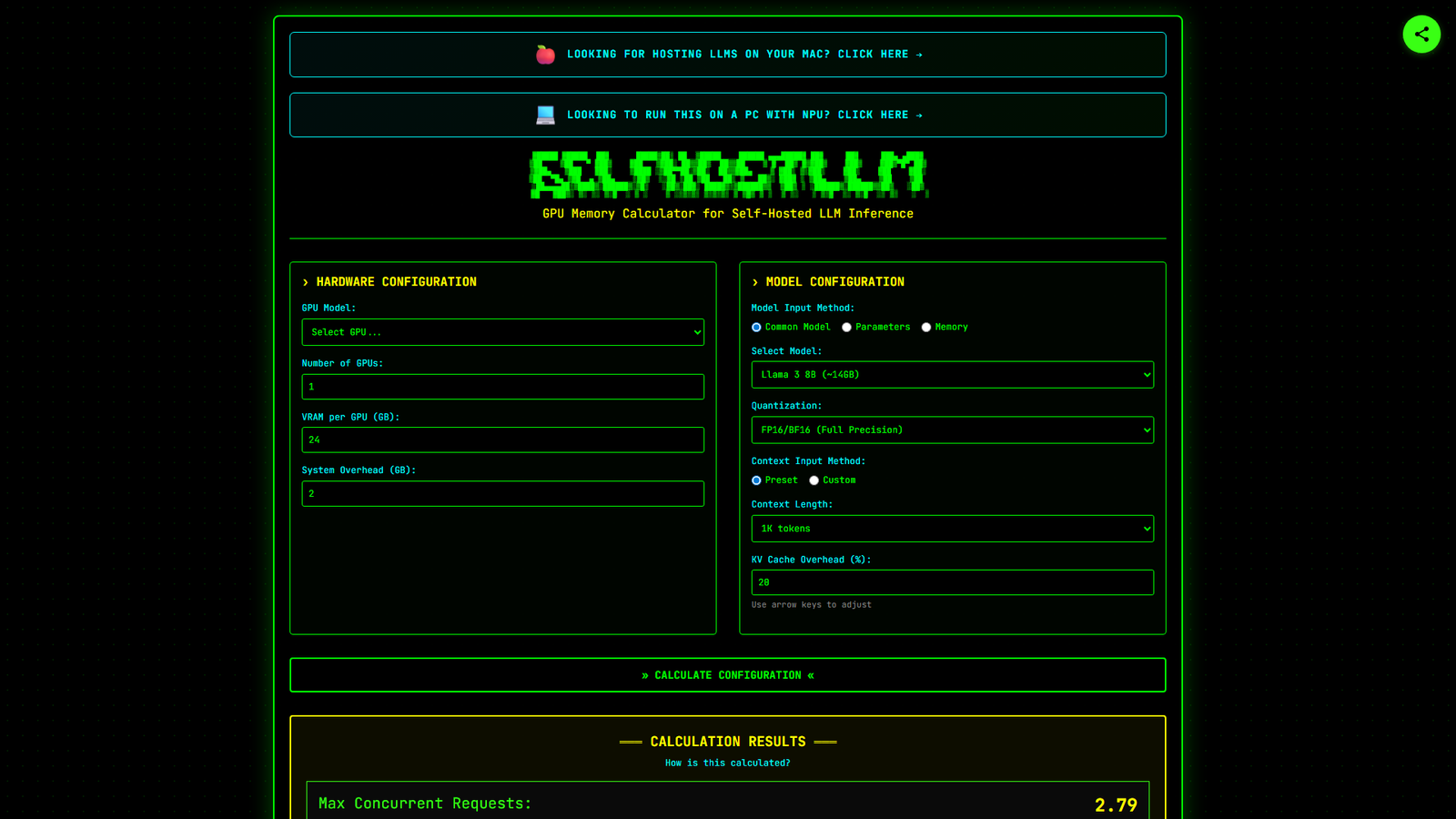
The page functions as a GPU Memory Calculator and Performance Estimator for self-hosting Large Language Models (LLMs). It provides detailed formulas and step-by-step breakdowns for calculating maximum concurrent requests and expected token generation speed. Users can configure hardware (GPU model, number of GPUs, VRAM, system overhead) and model parameters (model type, quantization, context length) through interactive input fields. The page also offers specific handling for Mixture-of-Experts (MoE) models and includes important notes on real-world performance variances.
Categories & Tags
Color Palette
Primary Text
#E0E0E0
Background
#1A1A1A
Accent Blue (Links/Interactive)
#007BFF
Accent Green (Positive Status)
#28A745
Typography
Sans-serif (e.g., Arial, Helvetica)
All text (headings, body, form labels, results)
Design Review
Similar Products

Clear for Slack
Clear messages get answered quicker

Griply 2026
Achieve your goals with a goal-oriented task manager

vibecoder.date
Find who you vibe with, git commit to love

Blober.io
The easiest way to transfer files between cloud providers.

Supaguard
Scan, Detect & Protect Your Supabase Data

Timelines Time Tracking 4
Track your time to achieve your New Year resolutions.

SoftReveal — Reveal less. Engage more.
Hide Content, Reveal on Click

CalPal
The notebook calculator that thinks for you (now with AI).

Reword
Rewrite messages without leaving your workflow

Radial
Your shortcuts, one gesture away

Resell AI
Reselling workflow with market-based price suggestions
Its Hover
Icons that move and react mirroring user intent